DeepSeek-Prover-V1.5 通过结合强化学习和蒙特卡洛树搜索,显著提升了证明生成的效率和准确性。
AI 技术与数学发现的进展,正前所未有地交织在一起。
前段时间,著名数学家陶哲轩在牛津数学公开讲座中做了主题为「AI 在科学和数学中的潜力」的主题分享。他指出,将 AI 整合到数学领域将使形式化证明的编写速度超过人类证明(人类证明容易出错)。这将成为一个关键转折点,意味着形式化证明的使用将不仅限于验证现有的证明,还将用于创造新的数学知识。这将通过广泛的人类数学家与 AI 数学家之间的协作来实现。我们将迎来一个「大数学」时代!

正如陶哲轩所说,将 AI 应用于形式化定理证明已经成为数学家的日常操作。在另一头,AI 科学家们也在努力提高 AI 在形式化定理证明中的性能和效率,比如 DeepSeek 刚刚推出的新模型 ——DeepSeek-Prover-V1.5。
DeepSeek-Prover-V1.5 是一个 70 亿参数的开源模型。它通过结合强化学习(基于证明助手反馈的强化学习,RLPAF)和蒙特卡洛树搜索(特别是提出的 RMaxTS 变体),显著提升了证明生成的效率和准确性。DeepSeek-Prover-V1.5 在 Lean 4 的形式定理证明方面优于所有开源模型。

以下是技术报告的详细内容。
技术报告概述

报告标题:DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
报告链接:https://arxiv.org/pdf/2408.08152
GitHub 链接:https://github.com/deepseek-ai/DeepSeek-Prover-V1.5
近年来,在大型语言模型领域取得的进展极大地推动了人工智能在数学推理和定理证明方面的发展。但语言模型在形式化定理证明方面仍面临重大挑战。例如,使用 Lean 和 Isabelle 这类系统进行证明时,需要进行严格的推导,以满足验证系统的形式规范。即便是像 GPT-4 这样的先进模型,在处理复杂的形式证明时也显得力不从心,这凸显了形式化证明中编码和数学推理的复杂性。一个高效的形式化定理证明模型不仅需要理解 Lean 证明助手等形式化系统的语法和语义,还需要将抽象的数学推理与精确的形式化表达方式相结合。
在形式化定理证明中,语言模型通常采用两种策略:证明步骤生成(proof-step generation)和完整证明生成(whole-proof generation)。
证明步骤生成通过预测并验证每一个策略,利用形式化验证器获取当前策略状态的更新信息,并常结合树搜索技术来构建有效的证明。而完整证明生成则在计算上更为高效,它基于定理陈述一次性生成整个证明代码,减少了证明模型与形式化定理验证器之间协调所需的通信量。
尽管 DeepSeek-Prover-V1 在 Lean 4 中通过完整证明生成取得了 SOTA 成果,但这种方法也有其独特的挑战。它需要在没有中间策略状态信息的情况下进行长期序列预测,而未来的策略依赖于这些隐藏的结果。在 Lean 的策略模式中,证明是通过一系列改变证明状态的策略来构建的。这种顺序性可能导致错误累积,一个小的误差就可能使证明偏离正确的路径。具体来说,自回归模型在生成长证明时可能会对中间策略状态有错误的认识。
为了在不牺牲完整证明生成的简便性和计算效率的同时,无缝地整合中间策略状态,研究者在 DeepSeek-Prover-V1.5 中开发了一种统一方法。这种方法通过截断和重新开始(truncate-and-resume)机制,结合了证明步骤生成和完整证明生成的优势。
该过程从标准的完整证明生成开始,语言模型根据定理陈述前缀完成证明代码,然后由 Lean 证明器进行验证。如果证明正确无误,流程就此结束。如果发现错误,就从第一个错误信息处截断代码,并丢弃后续代码。然后,使用成功生成的证明代码作为提示,生成下一个证明段。
为了提高模型新完成部分的准确性,研究者在提示的末尾添加了 Lean 4 证明器的最新状态作为注释。值得注意的是,该方法并不局限于从上次成功应用的策略中重新开始。研究者将截断和重新开始机制集成到了蒙特卡洛树搜索(MCTS)中,由树搜索策略来安排截断点。此外,他们提出了一种新的无奖励(reward-free)探索算法,用于解决证明搜索中的奖励稀疏问题。他们赋予树搜索智能体内在的驱动力,也就是好奇心,以广泛探索策略状态空间。这些算法模块扩展了他们的完整证明生成模型,使其成为一个灵活的交互式定理证明工具,能够有效利用证明助手的反馈,生成多样化的解决方案。
核心贡献
研究者提出了一个全面的框架,用于开发基于语言模型的形式化数学证明工具,他们整合了几个关键组件:大规模数学预训练、形式化数学语料库的构建和增强、基于证明助手反馈的在线强化学习,以及用于定理证明长期规划的树搜索方法论。预训练模型、监督微调模型、强化学习模型以及蒙特卡洛树搜索算法的代码都公开提供,以供进一步研究和应用。
1、预训练
研究者通过进一步在高质量数学和代码数据上预训练,增强了基础模型在形式化定理证明和数学推理方面的能力,重点关注 Lean、Isabelle 和 Metamath 等广泛用于证明助手的形式语言。
2、监督微调
研究者通过实现两种数据增强技术,改进了 Lean 4 代码补全数据集。首先,他们使用 DeepSeek-Coder V2 236B 在 Lean 4 代码旁注释 CoT(chain-of-thought)评论,将形式化定理证明与自然语言推理对齐。其次,他们在 Lean 4 证明代码中插入中间策略状态信息,使他们的模型能够更有效地利用编译器反馈。然后,他们使用这个数据集对预训练模型进行微调。
3、强化学习
研究者采用 GRPO 算法对监督微调模型进行 RLPAF(reinforcement learning from proof assistant feedback,基于证明助手反馈的强化学习)。Lean 证明器的验证结果作为奖励监督,增强了模型与验证系统的形式规范的一致性。
4、蒙特卡洛树搜索
研究者通过引入一种新的抽象和相应的搜索算法,推进了形式化定理证明中的树搜索方法。他们的截断和重新开始机制作为状态 - 动作抽象,将树搜索过程无缝集成到完整证明生成框架中。他们展示了 RMaxTS,这是一种创新的蒙特卡洛树搜索算法,利用 RMax 策略来解决证明搜索问题中稀疏奖励的探索挑战。通过分配内在奖励,这种算法鼓励证明智能体生成多样化的规划路径,从而促进对证明空间的广泛探索。
评估和度量
1、高中水平 miniF2F 数据集
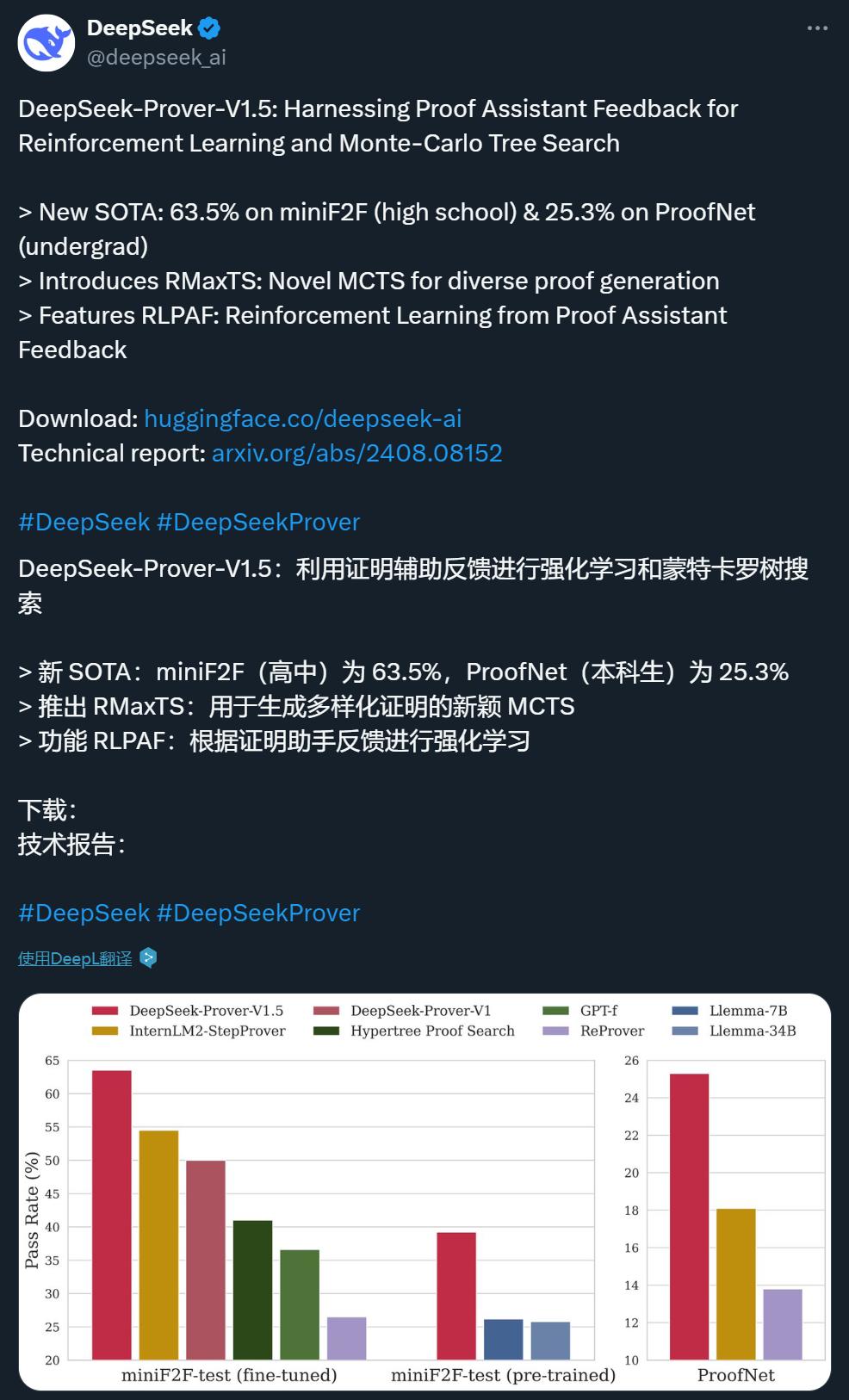
在单通道法完整证明生成设置中,DeepSeek-Prover-V1.5 在 miniF2F 的测试集上达到了 60.2% 的通过率,比 DeepSeek-Prover-V1 的 50.0% 提高了 10.2 个百分点。结合树搜索技术后,通过率进一步提升,达到了 63.5% 的新 SOTA。
2、大学本科水平 ProofNet 数据集
DeepSeek-Prover-V1.5 在 ProofNet 的单通道法完整证明生成设置中也展现出强大的性能,在验证集上通过率为 21.6%,在测试集上为 23.7%。结合树搜索技术之后,这些结果被进一步增强,在验证集上达到了 25.4% 的新 SOTA,在测试集上达到了 25.3%。
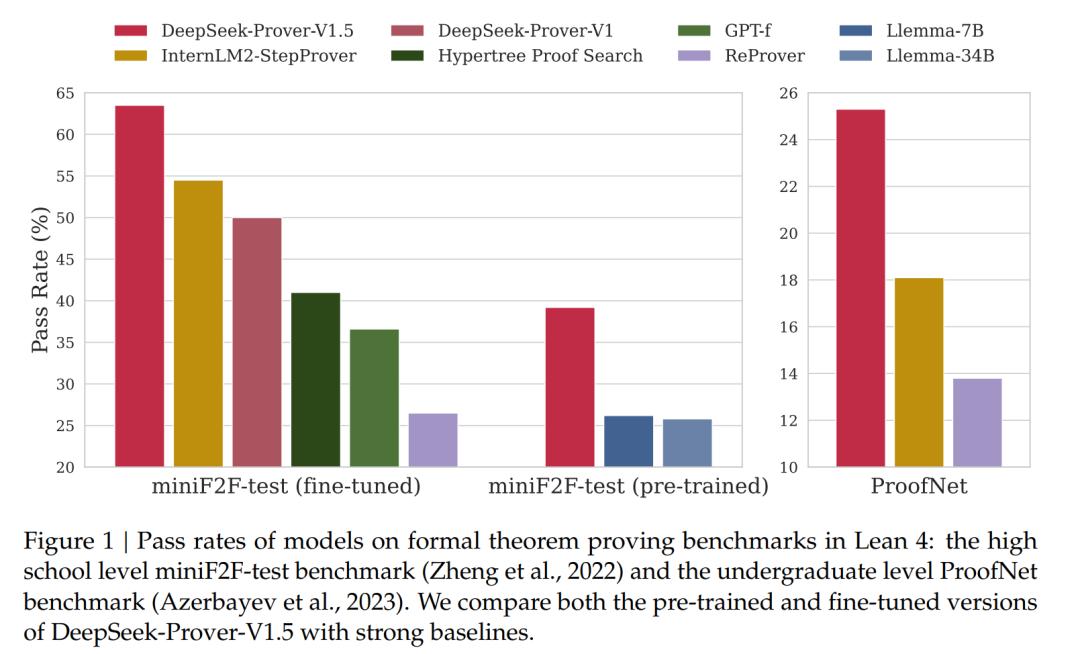
模型训练
为了提高语言模型生成形式证明和通过数学语言进行推理的能力,研究者对基础模型进行了进一步预训练,并将这个改进的模型命名为 DeepSeek-ProverV1.5-Base。
接着文章探讨了 DeepSeek-Prover-V1.5 的监督微调 (SFT) 所涉及的方法和流程。具体来说,研究者通过添加详细的解释性注释来扩充 DeepSeekProver-V1 的证明数据集。此增强旨在改善自然语言描述与 Lean 4 代码之间的一致性,从而促进更好的形式数学推理。此外,研究者将中间策略状态信息作为辅助预测任务纳入其中,以支持蒙特卡洛树搜索过程中使用的截断和重新开始机制,并将生成的模型称为 DeepSeek-ProverV1.5-SFT。
基于证明助手反馈的强化学习
为了进一步提高 DeepSeek-Prover-V1.5-SFT 的性能,该研究引入了一个强化学习阶段,从而得到了 DeepSeek-Prover-V1.5-RL 模型。这一阶段利用强化学习(RL)根据 Lean 4 证明器的验证反馈来提升性能。以下是该 RL 过程的具体细节。
训练提示。在强化学习阶段,该研究使用来自监督微调数据集的部分定理陈述作为训练提示。经过筛选保留了大约 4,500 个独特的定理陈述。每个定理都带有 CoT 和非 CoT 引导提示,以增强模型在这两种模式下的证明生成能力。
奖励。当通过 RL 训练 LLM 时,训练好的奖励模型通常会提供反馈信号。相比之下,形式化定理证明受益于证明助手对生成的证明的严格验证,从而提供了显著的优势。具体来说,如果验证正确,则每个生成的证明将获得 1 的奖励,否则将获得 0 的奖励。虽然这种二元奖励信号是准确的,但它也很稀疏,尤其是对于那些对监督微调模型具有挑战性的定理而言。为了缓解这种稀疏性,研究者选择了对监督微调模型具有挑战性但可实现的训练提示,如上所述。
强化学习算法。该研究采用组相对策略优化(GRPO)作为本文的 RL 算法,与 PPO 相比,该算法显示出更高的有效性和效率。具体而言,GRPO 为每个定理提示抽取一组候选证明,并根据组内输出的相对奖励优化模型。
评估。图 3 给出了 miniF2F 和 ProofNet 数据集上每个训练阶段的比较分析。在大多数设置中,CoT 模式始终优于非 CoT 模式。

面向探索的蒙特卡洛树搜索
为了在整体证明生成设置中实现树搜索方法,该研究引入了证明树抽象来定义定制的状态和动作空间,并利用了截断和重新开始机制。研究者首先将不完整的证明分解为与各个证明步骤相对应的树节点序列,然后利用存储在这些树节点中的部分内容继续证明生成过程。图 4 说明了从整体证明生成构建证明搜索树的过程。
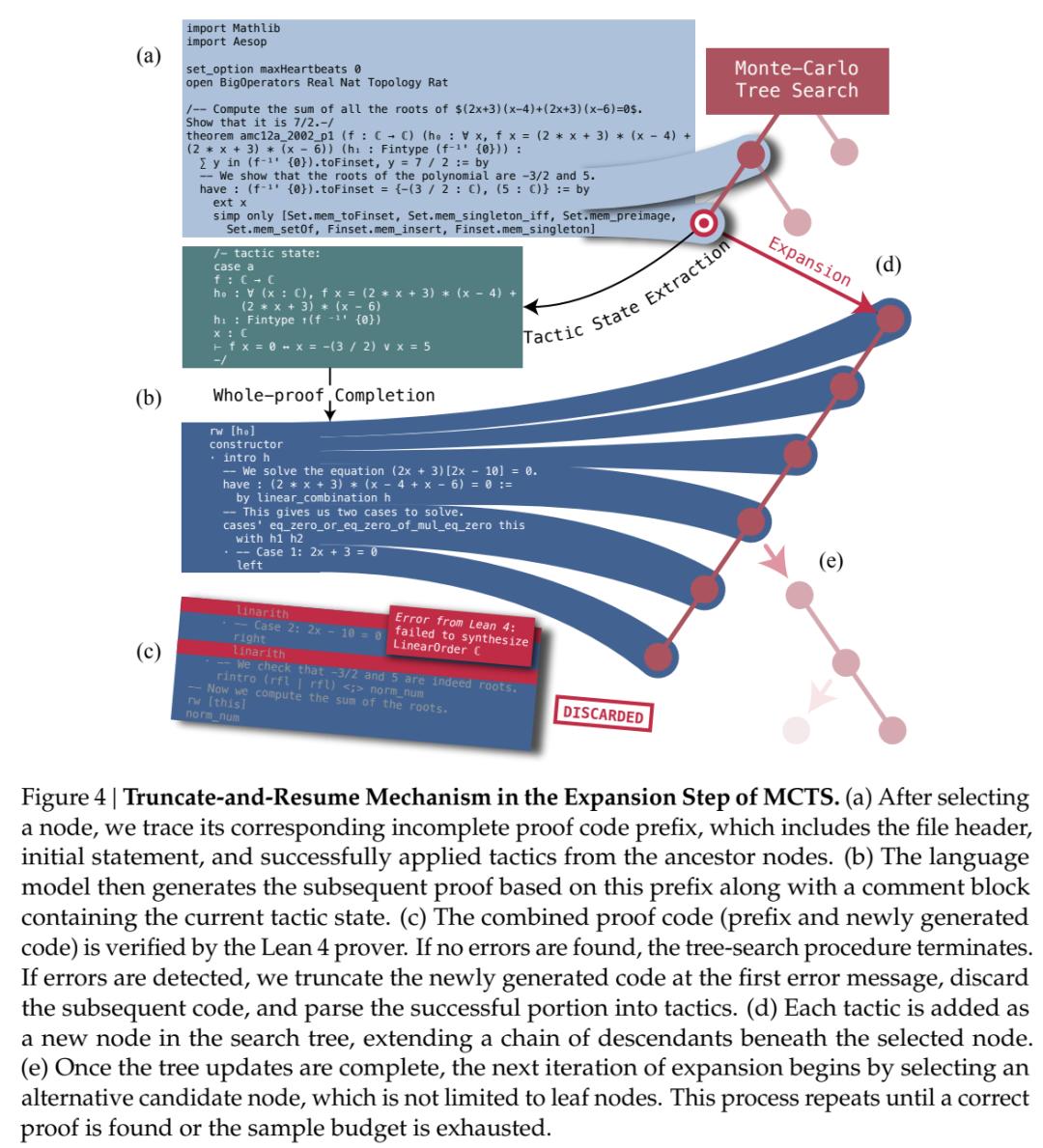
截断:该研究在策略级别构建证明搜索树,其中每条树边代表策略状态的单个转换步骤。首先,该研究将模型生成的整个证明提交给 Lean 证明器,并将其解析为策略。然后在最早的验证错误处截断证明,确保所有后续策略代码都可以成功应用,以将证明推进到所需的定理。策略代码被分割成几个代码片段,每个代码片段包含一个有效的策略代码及其相关的思维链注释,对应于代表策略状态转换的单个树边。通过这种抽象,每个策略代码被转换为一系列树节点,形成从根到特定节点的路径。
重新开始:在 Lean 4 中,不同的策略可以导致相同的策略状态,这意味着证明树中的每个节点可能对应多种能够实现相同结果的策略代码。为了解决这个问题,研究者在每个节点存储一组这些等效的策略代码。当树搜索智能体展开一个节点时,它会随机选择一个策略作为语言模型的提示。
蒙特卡洛树搜索的内在奖励
接下来文章介绍了内在奖励驱动的探索算法 —— 应用于树搜索的 RMax(RMax applied to Tree Search,RMaxTS),将无奖励探索纳入证明搜索问题。
RMax 应用于 MCTS。该研究采用 RMax 这一经典探索机制来构建蒙特卡洛树搜索的内在奖励。在证明搜索的上下文中,证明完成之前不提供外部奖励,此算法过程类似于 ZeroRMax ,其中智能体的探索仅由内在奖励驱动,即设置
。树扩展步骤的内在奖励取决于是否向搜索树中添加新节点
这种启发式方法可以潜在地减少冗余生成并提高样本效率。
实验结果
在本节中,研究者使用 miniF2F 和 ProofNet 这两个基准来评估 DeepSeek-Prover-V1.5 的定理证明能力。前者包括高中水平的练习和竞赛问题,后者则涉及本科水平的定理。
为了确保一致性,研究者使用了与评估中相同的训练模型和推理配置,展示了完整证明生成和蒙特卡洛树搜索方法的结果。
首先,论文介绍了 DeepSeek-Prover-V1.5 与之前的一些 SOTA 模型的对比分析,重点展示了其性能和进步。
通用模型
GPT-3.5 和 GPT-4 是 OpenAI 开发的高级生成式 AI 模型,因其在包括代码生成在内的各种任务中的有效性而闻名。尽管这些模型并非专为定理证明而设计,但其广泛的参数范围提供了重要的能力。
COPRA 促进了这些模型在形式定理证明中的评估,它是一个上下文学习智能体,利用这些大语言模型提出战术应用。
此外,研究者还讨论了 Llemma,这是一系列在广泛的通用数学语料库上训练的语言模型,通常用作形式定理证明的基础模型。
形式化数学的专用模型
GPT-f 是将 Transformers 应用于定理证明任务的证明步骤生成的初步尝试,它利用最佳优先搜索模块来构建完整的证明。后续的一些进展包括 ReProver、LLMStep 和 Lean-STaR。
Hypertree Proof Search 利用 Lean 探索了蒙特卡洛树搜索在形式定理证明中的应用。同期的 InternLM2-Math 和 InternLM2-StepProver 也表现出卓越的性能。
然后,研究者将这些模型与 DeepSeek-Prover-V1.5 进行了对比。
miniF2F 上的结果
表 1 提供了各种定理证明方法在 miniF2F 测试数据集上的对比分析。
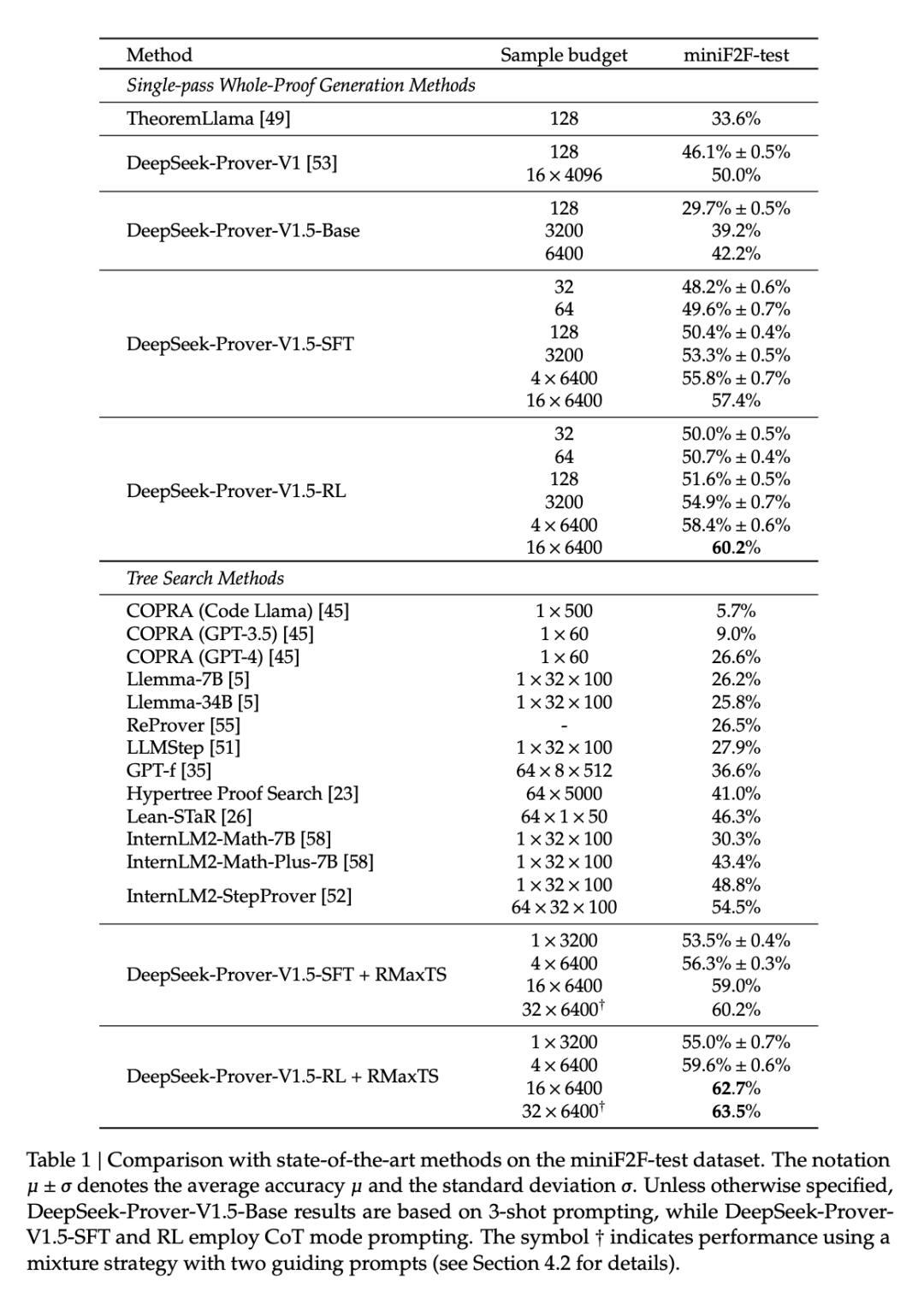
在单通道完整证明生成设置中,DeepSeekProver-V1.5-RL 的通过率最高,达到 60.2%,比 DeepSeek-Prover-V1 的 50.0% 提高了 10.2 个百分点。DeepSeek-Prover-V1.5-RL 将采样预算限制在 128 次尝试,证明了 51.6% 的问题,明显优于其他 whole-proof 生成方法,与领先的树搜索方法不相上下。在树搜索方法类别中,DeepSeek-Prover-V1.5-RL + RMaxTS 以 62.7% 的通过率遥遥领先,确立了新的 SOTA 水平,与现有方法拉开了很大差距。
值得注意的是,DeepSeek-Prover-V1.5-RL 只需要 3200 次完整证明采样就能达到 54.9% 的通过率,超过了 InternLM2-StepProver 之前的 SOTA 水平,后者需要执行 64 × 3200 次树搜索才能达到 54.5% 的通过率。
ProofNet 上的结果
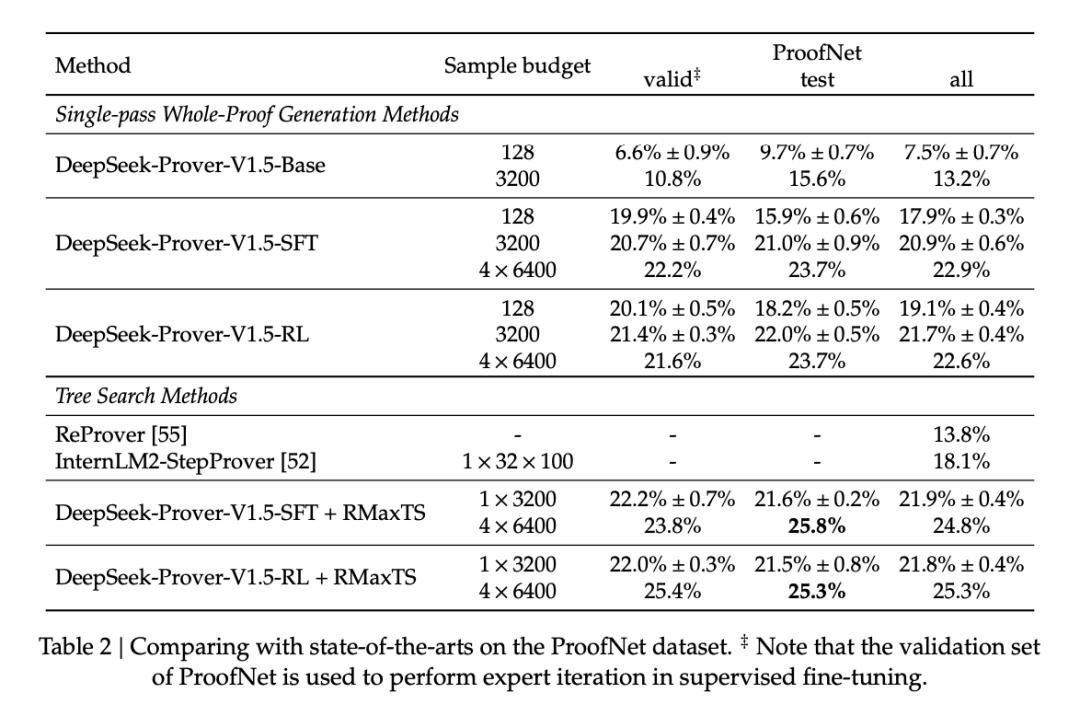
表 2 列出了各种定理证明方法在 ProofNet 数据集上的对比分析。DeepSeek-Prover-V1.5-RL 在整个 ProofNet 数据集上的通过率分别达到了 22.6% 和 25.3%。这些结果超过了现有的 SOTA 方法 ReProver(13.8%)和 InternLM2-StepProver(18.1%)。当完整证明生成尝试次数限制为 3200 次时,DeepSeek-Prover-V1.5 也证明了 21.7% 的定理,比之前最先进的 InternLM2-StepProver 提高了 3.6%。
重新审视训练策略在大规模采样中的效果
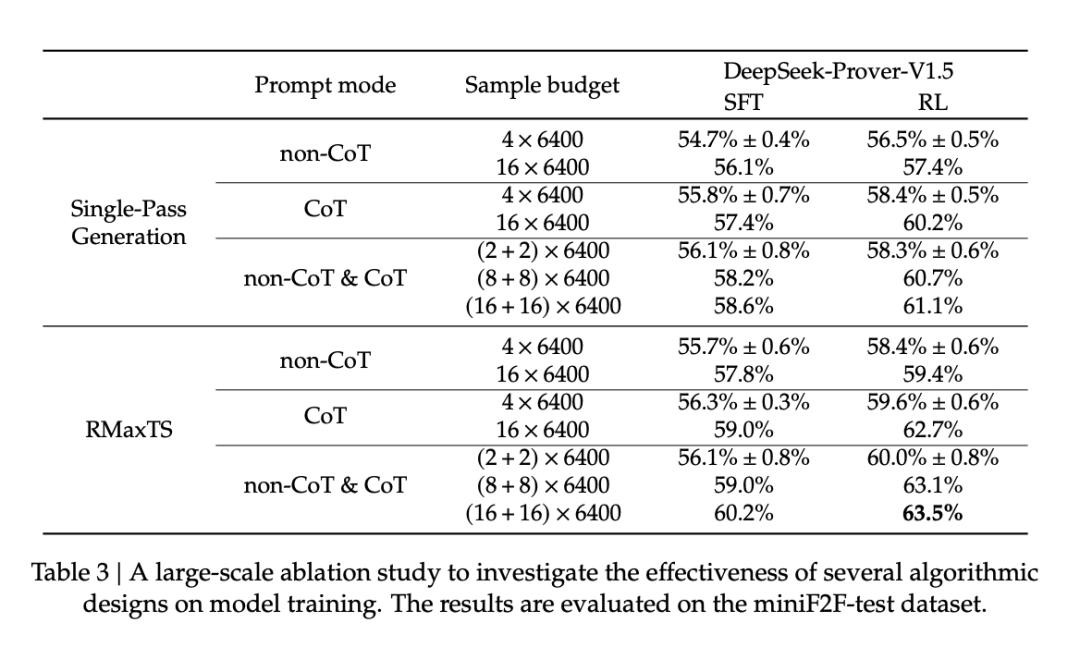
研究者重新审视了多个训练模块在大规模采样环境中的效果,重点是单通道完整证明生成和蒙特卡洛树搜索。
表 3 比较了两种生成模式,即非 CoT 和 CoT 在 miniF2F-test 数据集上的性能,表明随着样本预算的增加,CoT 相对于非 CoT 模式的优势被放大。
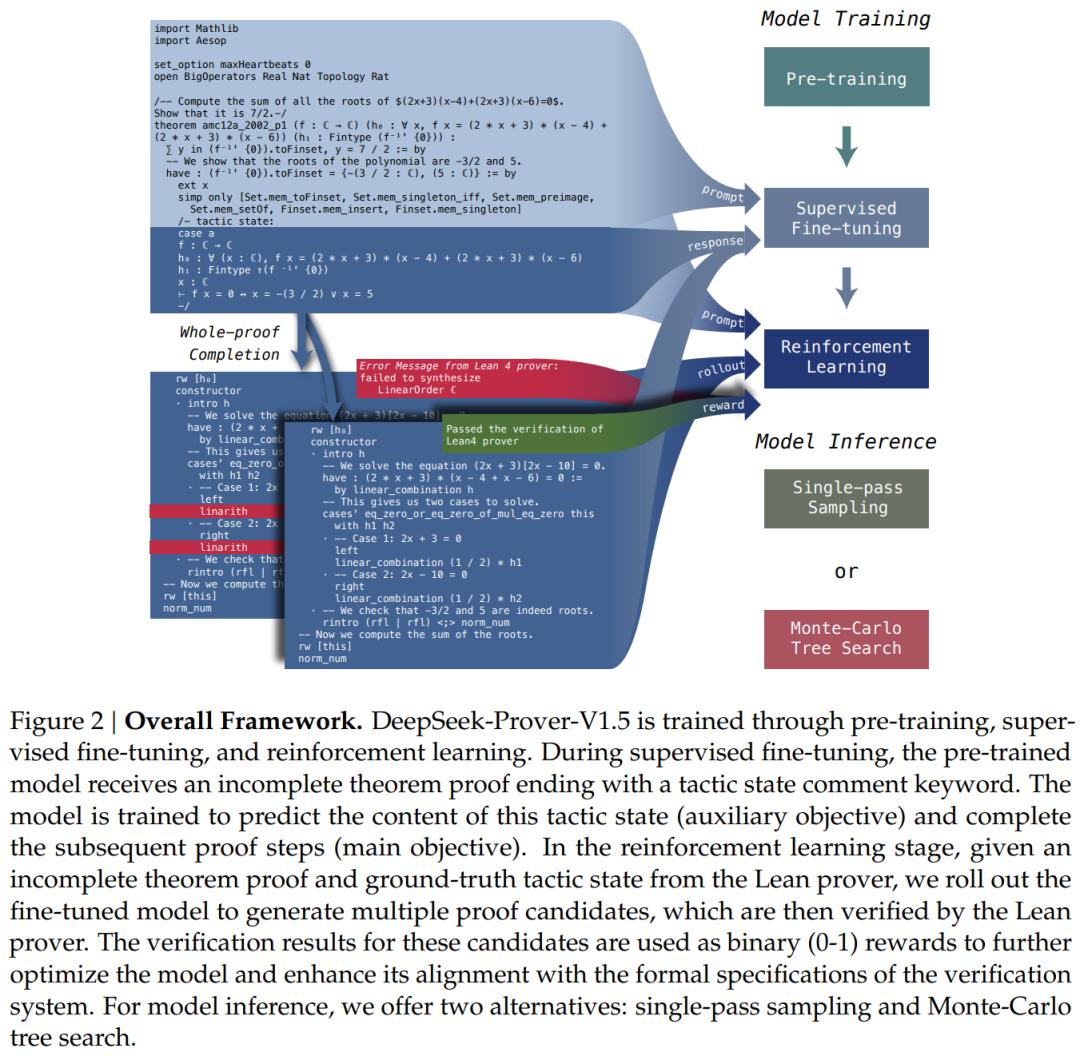
消融实验
在消融实验中,研究者检验了 RMaxTS 的算法设计。实验是在 miniF2F 测试数据集上使用 DeepSeek-Prover-V1.5-RL 以 CoT 模式进行的。如图 5 所示,左侧显示了 6400 个生成样本内 Pass@K 准确率的曲线,右侧显示了样本量更大时的结果。